Cerium による並列処理向け I/O の実装
|
Masataka Kohagura,Shinji Kono,
|
はじめに
ファイルを読み込んで計算を行うようなアプリケーションは、I/O の速度を無視することができない。
ファイルを全て読み込んでから並列計算をすると、読み込んでいる時間がオーバーヘッドとなってしまう。
本研究室では、並列プログラミングフレームワーク Cerium を使用することによって並列計算を可能にしているが、Cerium で I/O と並列計算を同時に走らせるにはどのように実装すればいいか考慮した。
-
I/O と並列計算を同時に動作させる。
-
I/O は連続で動作させる。
上記 2点を実装して、I/O と並列計算が同時に実行し、なおかつ I/O の処理を乱されないようにすることによって、全体のパフォーマンスを上げたい。
I/O の読み込みと並列計算の方法は以下の 3 つの方法を試みた。
-
mmap 後に並列計算
-
read 後に並列計算
-
read と 並列計算 が同時に実行
-> 本研究では並列計算を Word Count で実装を行った。
mmap の特徴

-
mmap は、仮想メモリ空間にファイルの中身を対応させ、そのメモリ空間に
アクセスされたら、 OS が読み込みを行う。
-
code の記述はシンプルだが、スレッドが読み込み終わるまで待たされる。
-
読み込みが OS 依存となるので、環境に左右されやすく、読み込みを細かく制御することが難しい。
読み込みながら計算を行う
mmap を使用せずに、read を独立したスレッドで実行させる。そして、読み込んだ部分に対して Word Count を並列に起動する。

- read は全て読み込み終えるまで連続で動作しファイルを読み込む
- read の待ちは CPU を消費しない
- 読み込み終わったブロックに対して、Word Count を起動する
-
WordCount Task を一度に全て生成すると、その Task でメモリを圧迫するので、
ある程度の数でまとめた Block という単位で徐々に Task を起動していく。
読み込みを行ってから計算を行う

- 読み込みを行ってから計算を行うので、読み込みの間、CPU に待ち時間が発生してオーバーヘッドとなる。
I/Oを含むアプリケーションの並列化
I/O は、ディスクからの読み込む時間がかかる。
-> I/O をどのように実装したら、並列処理とI/Oが干渉をなくして全体のパフォーマンスを上げれるか??
そこで本研究では、

- ファイル読み込みとアプリケーションの分離するための実装法
- I/O専用の Threadを追加
- mmap と比較や、様々な実験環境で計測
以上3点を行った。
Cerium Task Manager の構造
Cerium Task Manager:
CellおよびLinux、 Mac OS X 上で動く並列プログラミングフレームワーク
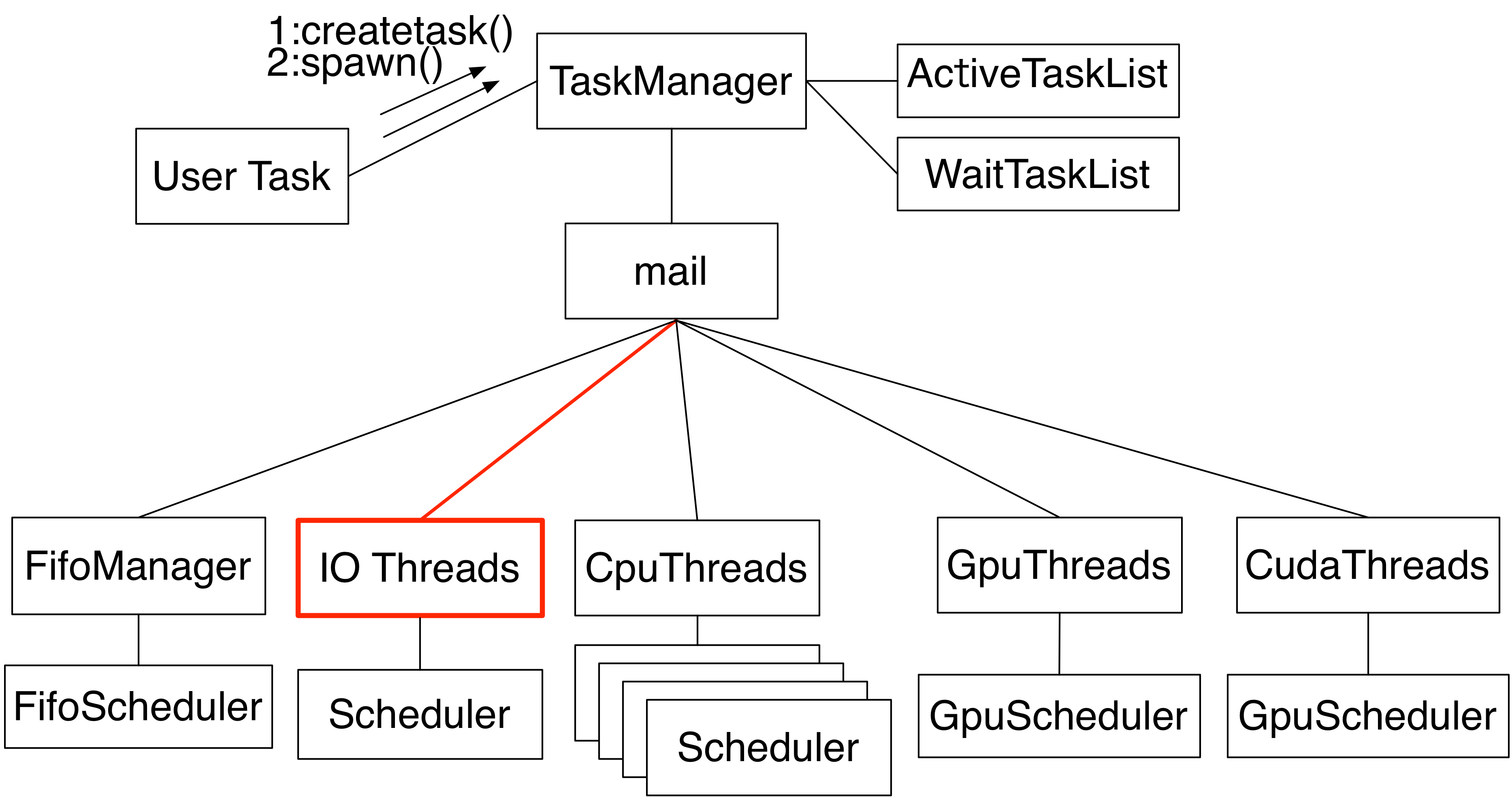 |
- User が Taskを生成
- 依存関係のチェック
- 各Schedulerに Task を転送
|
User が Word Count などの Task を生成して、それらを GPU や CPU などに計算させるように User 自身で設定することができる。
ファイルを読みながら、Word Count や grep などを 並列実行したい。
計算よりも読み込みを優先しなければならない。読み込みで待ちが入ってしまうので、IO Thread を追加。
大きなファイルに対するデータ並列

- ファイルをある一定の大きさずつ読み込む
- 読み込んだテキストファイルに対して、それぞれ 並列に計算 を行う
- 計算の結果を集計する
Blocked Read の実装
読み込みながら並列計算を実行する方法を、Blocked Read と名付けた。

-
読み込んでいない部分に Word Count が走らないように、Blocked Read Task が読み込み終わるまで、Task Blockを待たせる。
-
Word Count Task 1つで処理するファイルの大きさを L
Task Block 1つ当たりに含まれている Word Count Task の数を n
とすると、Blocked Read Task 1つ当たりの読み込み量は L * n となる。
I/O 専用 thread での Blocked Read の実装
-
Blocked Read の実装だけでは、Blocked Read Task 間に Task が割り込まれてしまう可能性がある。
-
I/O を含むアプリケーションの実行時間のほとんどが I/O の時間になることが多い。
-
読み込みの間に Task が割り込まれると、下の図のように全体の実行速度が遅くなってしまう。

- Blocked Read Task に I/O 専用 thread を用意して、 Word Count とは別に Thread を割り当てることにより、Blocked Read Task 間に Task が割り込まれないようにした。
- Thread レベルで割り込まれないように、pthread_setschedparam にて IO_0 の priority を設定している。
実験概要
実験環境
- OS:MacOS 10.9.2
- CPU:2*2.66GHz 6-Core Intel Xeon
- GPU:NVIDIA Quadro K5000 4096MB
- Memory:16GB 1333MHz DDR3
- HDD : 1TB 7200 rpm SATA 3.0 Gbps
- Word Count の時間を、ファイルの読み込みから結果出力するまでを測定
Word Count を実行した後に、読み込むファイルをキャッシュから追い出すために、
% sudo purge
を実行して繰り返し、測定を行っている。
実験1: 使用 CPU 数を変更させた時の実行速度の比較
全ての実験のfile size は 1GB であり、表内の数値の単位は全て秒である。
Blocked read Task 1つ当たりの読み込み量 : 16kbyte * 48
| read mode \ CPU num |
|
CPU 1 |
CPU 4 |
CPU 8 |
CPU 12 |
GPU(CUDA) |
| mmap |
|
15.353 |
11.287 |
11.707 |
11.137 |
103.410 |
| read |
|
16.846 |
11.730 |
11.487 |
11.437 |
106.050 |
| Blocked Read(SPE_ANY) |
|
13.297 |
11.984 |
10.887 |
11.146 |
94.626 |
| Blocked Read(IO_0) |
|
11.503 |
11.437 |
11.365 |
11.412 |
94.496 |
- SPE_ANY は、Cerium Task Manager がそれぞれの Task に自動的に CPU を割り振ってくれる。
-> I/O が連続で動作する保証がなくなってしまう。
- CPU 4 以上からはほとんど同じ実行結果を示した。
- 実行時間のほとんどは I/O の読み込みの時間となっている。
read でファイル読み込みだけの時間を測定すると、11.166 秒となった。
-
GPU を使用した場合、並列計算と I/O を分離させたほうが 10% ほど速くなった。
ファイルがキャッシュに入った時の実行速度は以下のようになった。
| read mode \ CPU num |
|
CPU 12 |
GPU |
| mmap |
|
0.854 |
94.479 |
| read |
|
1.487 |
94.614 |
| Blocked Read(SPE_ANY) |
|
0.847 |
93.920 |
| Blocked Read(IO_0) |
|
0.866 |
93.912 |
実験1: 使用 CPU 数を変更させた時の実行速度の比較

実験2: Blocked Read size を変更してみる
filesize : 1GB
Blocked read Task 1つ当たりの読み込み量 : 128 kbyte * 48
| read mode \ CPU num |
|
CPU 1 |
CPU 4 |
CPU 8 |
CPU 12 |
| mmap |
|
20.179 |
22.861 |
22.789 |
22.713 |
| read |
|
21.351 |
15.737 |
14.785 |
12.520 |
| Blocked Read(SPE_ANY) |
|
18.531 |
15.646 |
15.287 |
14.028 |
| Blocked Read(IO_0) |
|
13.930 |
14.634 |
14.774 |
10.295 |
-
Blocked Read size を大きくすると、mmap は遅くなってしまう。
-
本研究ではI/O をBlocked Read(IO_0)で実装してなおかつ、CPU 12 の時、最速となった。
実験1との比較
Blocked read Task 1つ当たりの読み込み量 : 16 kbyte * 48
| read mode \ CPU num |
|
CPU 1 |
CPU 4 |
CPU 8 |
CPU 12 |
| mmap |
|
15.353 |
11.287 |
11.707 |
11.137 |
| read |
|
16.846 |
11.730 |
11.487 |
11.437 |
| Blocked Read(SPE_ANY) |
|
13.297 |
11.984 |
10.887 |
11.146 |
| Blocked Read(IO_0) |
|
11.503 |
11.437 |
11.365 |
11.412 |
実験2: Blocked Read size を変更してみる

実験3: CPU 数を固定して、Blocked Read size を変更してみる
word count task 1つ当たりの処理量を 4kbyte ~ 256kbyte で変化させてみた。
CPU 12 で全て測定している。
| read mode \ Blocled Read size |
|
4k * 48 |
8k * 48 |
16k * 48 |
32k * 48 |
64k * 48 |
128k * 48 |
256k * 48 |
| mmap |
|
11.867 |
10.570 |
11.803 |
14.915 |
16.626 |
16.923 |
18.474 |
| read |
|
12.020 |
11.585 |
11.729 |
11.661 |
12.497 |
11.347 |
11.658 |
| Blocked Read(SPE_ANY) |
|
11.508 |
15.932 |
11.407 |
12.816 |
12.454 |
12.891 |
11.962 |
| Blocked Read(IO_0) |
|
11.342 |
12.242 |
11.636 |
12.331 |
10.870 |
11.295 |
11.723 |
-
Blocked Read size を大きくすればするほど、mmap は遅くなる。
-
どの大きさでも read と Blocked Read(IO_0) は安定した速度がでる。
実験3: CPU 数を固定して、Blocked Read size を変更してみる

実験4: mmap 後に madvise で読み込み方法を設定する
Blocked read Task 1つ当たりの読み込み量 : 16 kbyte * 48
OS : Mac OS 10.9.2
| madvise flag |
|
time(s) |
| MADV_NORMAL(default) |
|
11.841 |
| MADV_RANDOM |
|
42.891 |
| MADV_SEQENTIAL |
|
38.935 |
| MADV_WILLNEED |
|
10.916 |
| MADV_DONTNEED |
|
17.506 |
| MADV_FREE |
|
16.863 |
-
madvise はマッピングされたメモリに対してどのように処理を行うか指定することができる。kernel はそれに応じて読み込みを行う。
-
kernel に読み込みを任せたほうが速い。
-
mmap でファイルの読み込みを行うときは、madvise で MADV_WILLNEED(先読みしておいたほうがよい) で設定すると最も速くなった。
実験5: 別のコンピュータにて測定
- OS : CentOS 6.5
- CPU : Core i7-3770 3.40GHz
- Memory : 16GB
- HDD : 2TB 7200 rpm SATA 6.0 Gbps
ファイルをキャッシュから追い出すために、以下のコマンドを実行した。
% sysctl -w vm.drop_caches=3
Blocked read Task 1つ当たりの読み込み量 : 16 kbyte * 48
| read mode \ CPU num |
|
CPU 1 |
CPU 2 |
CPU 3 |
CPU 4 |
CPU 8 |
| mmap |
|
6.852 |
6.765 |
7.632 |
12.504 |
7.649 |
| read |
|
10.545 |
8.699 |
8.667 |
8.152 |
7.607 |
| Blocked Read(SPE_ANY) |
|
8.686 |
10.606 |
12.995 |
11.799 |
14.723 |
| Blocked Read(IO_0) |
|
6.751 |
6.800 |
7.311 |
7.016 |
6.755 |
-
read だけの時間を測定すると、6.742 秒となった。
-
Mac OS X のときとほとんど同じ傾向を示しているが、Blocked Read(SPE_ANY)のときだけ極端に遅くなった。
実験1の測定結果(Mac OS X)
| read mode \ CPU num |
|
CPU 1 |
CPU 4 |
CPU 8 |
CPU 12 |
| mmap |
|
15.353 |
11.287 |
11.707 |
11.137 |
| read |
|
16.846 |
11.730 |
11.487 |
11.437 |
| Blocked Read(SPE_ANY) |
|
13.297 |
11.984 |
10.887 |
11.146 |
| Blocked Read(IO_0) |
|
11.503 |
11.437 |
11.365 |
11.412 |
実験5: 別のコンピュータにて測定

考察
mmap での実行時は、Blocked Read size を小さくしたほうが速度が向上した。これは、まとめと読み込むサイズが小さくなればなるほど、sequential access に近い動作になるからであると考えられる。
I/O の読み込みと並列計算を分離して、同時に処理させたほうが、全体的に安定した速度がでるが、mmapだと一度に読み込む大きさが小さければ速い。
mmapは読み込みの大きさによって全体の速度が変わってしまうが、どんな大きさでも安定した速度で改良する余地があると思われる。
まとめ
- I/O と Task を分離し、同時に動くように改良し、どの環境でも安定した速度が出た。
- I/O 専用の Thread の追加
-
mmap でも一度に読み込む大きさを小さくすれば、Blocked Read とほぼ同じ速度が出る。
今後の課題
- Cerium の API として実装
-
様々な実装の試み
(I/O threads を 2つ使用したプログラム、分割 mmap)
-
様々な環境での測定
-
grepの実装
