GNU コンパイラコレクション (GCC)
GCCでのコンパイルの流れ
- フロントエンド
- ミドルエンド
- バックエンド

与儀健人 (並列信頼研究室) <kent@cr.ie.u-ryukyu.ac.jp>
なにが問題になるのか?
状態遷移記述をベースとした、より細かい単位でのプログラミングを実現する
条件
継続を基本とする記述言語CbC
継続
CbCでの軽量継続
typedef code (*NEXT)(int);
int main(int argc, char **argv) {
int i;
i = atoi(argv[1]);
goto factor(i, print_fact);
}
code factor(int x, NEXT next) {
goto factor0(1, x, next);
}
code factor0(int prod,int x,NEXT next) {
if (x >= 1) {
goto factor0(prod*x, x-1, next);
} else {
goto (*next)(prod);
}
}
code print_fact(int value) {
printf("factorial = %d\n", value);
exit(0);
}
実際のプログラム記述は?
codeキーワードで宣言gotoキーワードと引数取り組み
GCCでのコンパイルの流れ
GCCでのコンパイルの流れ

軽量継続を実装するには?
そこで、末尾呼出をGCCに強制させる必要がある
末尾呼出ってなに?

末尾呼出ってなに?
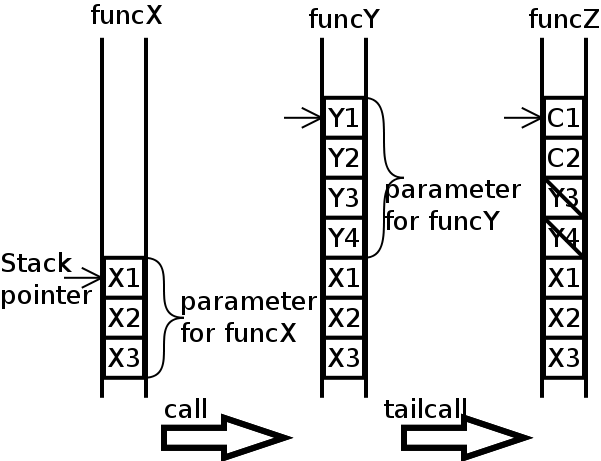
この末尾呼出(TCE)を強制して軽量継続を実装!
プログラム実行時のスタックの変化
軽量継続は実装されたが、やはりmicro-cに比べると遅い
fastcallの導入
fastcallの強制
__code current(int a, int b, int c) __attribute__((fastcall));
これで軽量継続制御が高速化される!
CbCGCCとmicro-cで性能の比較
実行環境
速度測定結果(単位:秒)
| 新CbCGCC | 旧CbCGCC | |||
|---|---|---|---|---|
| 最適化無し | 最適化有り | 最適化無し | 最適化有り | |
| x86/OS X | 5.907 | 2.434 | 4.668 | 3.048 |
| x86/Linux | 5.715 | 2.401 | 4.525 | 2.851 |
評価
速度測定結果(単位:秒)
| 最適化なしのGCC | 最適化付きのGCC | micro-c | |
| x86/OS X | 5.901 | 2.434 | 2.857 |
| x86/Linux | 5.732 | 2.401 | 2.254 |
| ppc/OS X | 14.875 | 2.146 | 4.811 |
| ppc/Linux | 19.793 | 3.955 | 6.454 |
| ppc/PS3 | 39.176 | 5.874 | 11.121 |
結果(micro-cとの比較)
この違いはどこから?
なぜそれが必要か
環境付き継続の導入
typedef code (*NEXT)(int);
int main(int argc, char **argv) {
int i,a;
i = atoi(argv[1]);
a = factor(i);
printf("%d! = %d\n", a);
}
int factor(int x) {
NEXT ret = __return;
goto factor0(1, x, ret);
}
code
factor0(int prod,int x,NEXT next) {
if (x >= 1) {
goto factor0(prod*x, x-1, next);
} else {
goto (*next)(prod);
}
}
環境付き継続の使用例
__returnで表される特殊なコードセグメント__returnに継続すると、元の関数の環境にリターン内部関数を用いた実装
__returnが参照された場合にGCCが自動で内部関数を定義するint factor(int x) {
int retval;
code __return(int val) {
retval = val;
goto label;
}
if (0) {
label:
return retval;
}
NEXT ret = __return;
goto factor0(1, x, ret);
} この取り組みにより
本研究での取り組み
本研究での成果
CbC言語の今後
ありがとうございました
継続
CbCでの軽量継続
typedef code (*NEXT)(int);
int main(int argc, char **argv) {
int i;
i = atoi(argv[1]);
goto factor(i, print_fact);
}
code factor(int x, NEXT next) {
goto factor0(1, x, next);
}
code factor0(int prod,int x,NEXT next) {
if (x >= 1) {
goto factor0(prod*x, x-1, next);
} else {
goto (*next)(prod);
}
}
code print_fact(int value) {
printf("factorial = %d\n", value);
exit(0);
}
実際のプログラム記述は?
codeキーワードで宣言gotoキーワードと引数取り組み
GCCでのコンパイルの流れ
GCCでのコンパイルの流れ
GCCにおける構文解析部
<call_expr 0xb7bc7850
type <void_type 0xb7cc9270 void VOID
align 8 symtab 0 alias set -1 canonical type 0xb7cc9270
pointer_to_this <pointer_type 0xb7cc92d8>>
side-effects addressable tree_5
fn <var_decl 0xb7d65370 D.2156
type <pointer_type 0xb7da74e0 type <function_type 0xb7da7478>
unsigned SI
size <integer_cst 0xb7cb36ac constant 32>
unit size <integer_cst 0xb7cb3498 constant 4>
align 32 symtab 0 alias set -1 structural equality>
used unsigned SI file quicksort/quicksort_cbc.cbc line 29 col 2 size <integer_cst 0xb7cb36ac 32> unit size <integer_cst 0xb7cb3498 4>
align 32 context <function_decl 0xb7da2c80 returner>
(mem/f/c/i:SI (plus:SI (reg/f:SI 54 virtual-stack-vars)
(const_int -12 [0xfffffff4])) [0 D.2156+0 S4 A32])
chain <var_decl 0xb7d653c8 D.2157 type <pointer_type 0xb7cc92d8>
used unsigned SI file quicksort/quicksort_cbc.cbc line 29 col 2 size <integer_cst 0xb7cb36ac 32> unit size <integer_cst 0xb7cb3498 4>
align 32 context <function_decl 0xb7da2c80 returner>
(mem/f/c/i:SI (plus:SI (reg/f:SI 54 virtual-stack-vars)
(const_int -8 [0xfffffff8])) [0 D.2157+0 S4 A32]) chain <var_decl 0xb7d65420 D.2158>>> arg 0 <var_decl 0xb7d653c8 D.2157>
arg 1 <var_decl 0xb7d65420 D.2158
type <pointer_type 0xb7da7270 stack type <void_type 0xb7cc9270 void>
sizes-gimplified unsigned SI size <integer_cst 0xb7cb36ac 32> unit size <integer_cst 0xb7cb3498 4>
align 32 symtab 0 alias set -1 canonical type 0xb7cc92d8
pointer_to_this <pointer_type 0xb7bb7000>>
used unsigned SI file quicksort/quicksort_cbc.cbc line 29 col 2 size <integer_cst 0xb7cb36ac 32> unit size <integer_cst 0xb7cb3498 4>
align 32 context <function_decl 0xb7da2c80 returner>
(mem/f/c/i:SI (plus:SI (reg/f:SI 54 virtual-stack-vars)
(const_int -4 [0xfffffffc])) [0 D.2158+0 S4 A32])>
quicksort/quicksort_cbc.cbc:29:7>
全ての構文はこのGIMPLEで表される
つまり、主に修正すべきはこのフロントエンドとなる
GIMPLEからRTLへの変換と最適化
p = &all_lowering_passes;
NEXT_PASS (pass_remove_useless_stmts);
NEXT_PASS (pass_mudflap_1);
NEXT_PASS (pass_lower_omp);
NEXT_PASS (pass_lower_cf);
NEXT_PASS (pass_refactor_eh);
NEXT_PASS (pass_lower_eh);
NEXT_PASS (pass_build_cfg);
NEXT_PASS (pass_lower_complex_O0);
NEXT_PASS (pass_lower_vector);
#ifndef noCbC
//NEXT_PASS (pass_warn_function_return);
#else
NEXT_PASS (pass_warn_function_return);
#endif
NEXT_PASS (pass_build_cgraph_edges);
NEXT_PASS (pass_inline_parameters);
*p = NULL;
/* Interprocedural optimization passes. */
p = &all_ipa_passes;
NEXT_PASS (pass_ipa_function_and_variable_visibility);
NEXT_PASS (pass_ipa_early_inline);
{
struct opt_pass **p = &pass_ipa_early_inline.pass.sub;
NEXT_PASS (pass_early_inline);
NEXT_PASS (pass_inline_parameters);
NEXT_PASS (pass_rebuild_cgraph_edges);
}
NEXT_PASS (pass_early_local_passes);
{
struct opt_pass **p = &pass_early_local_passes.pass.sub;
NEXT_PASS (pass_tree_profile);
NEXT_PASS (pass_cleanup_cfg);
NEXT_PASS (pass_init_datastructures);
NEXT_PASS (pass_expand_omp);
NEXT_PASS (pass_referenced_vars);
NEXT_PASS (pass_reset_cc_flags);
NEXT_PASS (pass_build_ssa);
NEXT_PASS (pass_early_warn_uninitialized);
NEXT_PASS (pass_all_early_optimizations);
{
struct opt_pass **p = &pass_all_early_optimizations.pass.sub;
NEXT_PASS (pass_rebuild_cgraph_edges);
NEXT_PASS (pass_early_inline);
NEXT_PASS (pass_rename_ssa_copies);
NEXT_PASS (pass_ccp);
NEXT_PASS (pass_forwprop);
NEXT_PASS (pass_update_address_taken);
NEXT_PASS (pass_sra_early);
NEXT_PASS (pass_copy_prop);
NEXT_PASS (pass_merge_phi);
NEXT_PASS (pass_cd_dce);
NEXT_PASS (pass_simple_dse);
NEXT_PASS (pass_tail_recursion);
NEXT_PASS (pass_convert_switch);
NEXT_PASS (pass_profile);
}
NEXT_PASS (pass_release_ssa_names);
NEXT_PASS (pass_rebuild_cgraph_edges);
NEXT_PASS (pass_inline_parameters);
}
NEXT_PASS (pass_ipa_increase_alignment);
NEXT_PASS (pass_ipa_matrix_reorg);
NEXT_PASS (pass_ipa_cp);
NEXT_PASS (pass_ipa_inline);
NEXT_PASS (pass_ipa_reference);
NEXT_PASS (pass_ipa_pure_const);
NEXT_PASS (pass_ipa_type_escape);
NEXT_PASS (pass_ipa_pta);
NEXT_PASS (pass_ipa_struct_reorg);
*p = NULL;
/* These passes are run after IPA passes on every function that is being
output to the assembler file. */
p = &all_passes;
NEXT_PASS (pass_all_optimizations);
{
struct opt_pass **p = &pass_all_optimizations.pass.sub;
/* Initial scalar cleanups before alias computation.
They ensure memory accesses are not indirect wherever possible. */
NEXT_PASS (pass_strip_predict_hints);
NEXT_PASS (pass_update_address_taken);
NEXT_PASS (pass_rename_ssa_copies);
NEXT_PASS (pass_complete_unrolli);
NEXT_PASS (pass_ccp);
NEXT_PASS (pass_forwprop);
/* Ideally the function call conditional
dead code elimination phase can be delayed
till later where potentially more opportunities
can be found. Due to lack of good ways to
update VDEFs associated with the shrink-wrapped
calls, it is better to do the transformation
here where memory SSA is not built yet. */
NEXT_PASS (pass_call_cdce);
/* pass_build_alias is a dummy pass that ensures that we
execute TODO_rebuild_alias at this point. Re-building
alias information also rewrites no longer addressed
locals into SSA form if possible. */
NEXT_PASS (pass_build_alias);
NEXT_PASS (pass_return_slot);
NEXT_PASS (pass_phiprop);
NEXT_PASS (pass_fre);
NEXT_PASS (pass_copy_prop);
NEXT_PASS (pass_merge_phi);
NEXT_PASS (pass_vrp);
NEXT_PASS (pass_dce);
NEXT_PASS (pass_cselim);
NEXT_PASS (pass_tree_ifcombine);
NEXT_PASS (pass_phiopt);
NEXT_PASS (pass_tail_recursion);
NEXT_PASS (pass_ch);
NEXT_PASS (pass_stdarg);
NEXT_PASS (pass_lower_complex);
NEXT_PASS (pass_sra);
NEXT_PASS (pass_rename_ssa_copies);
NEXT_PASS (pass_dominator);
/* The only const/copy propagation opportunities left after
DOM should be due to degenerate PHI nodes. So rather than
run the full propagators, run a specialized pass which
only examines PHIs to discover const/copy propagation
opportunities. */
NEXT_PASS (pass_phi_only_cprop);
NEXT_PASS (pass_dse);
NEXT_PASS (pass_reassoc);
NEXT_PASS (pass_dce);
NEXT_PASS (pass_forwprop);
NEXT_PASS (pass_phiopt);
NEXT_PASS (pass_object_sizes);
NEXT_PASS (pass_ccp);
NEXT_PASS (pass_copy_prop);
NEXT_PASS (pass_fold_builtins);
NEXT_PASS (pass_cse_sincos);
NEXT_PASS (pass_split_crit_edges);
NEXT_PASS (pass_pre);
NEXT_PASS (pass_sink_code);
NEXT_PASS (pass_tree_loop);
{
struct opt_pass **p = &pass_tree_loop.pass.sub;
NEXT_PASS (pass_tree_loop_init);
NEXT_PASS (pass_copy_prop);
NEXT_PASS (pass_dce_loop);
NEXT_PASS (pass_lim);
NEXT_PASS (pass_predcom);
NEXT_PASS (pass_tree_unswitch);
NEXT_PASS (pass_scev_cprop);
NEXT_PASS (pass_empty_loop);
NEXT_PASS (pass_record_bounds);
NEXT_PASS (pass_check_data_deps);
NEXT_PASS (pass_loop_distribution);
NEXT_PASS (pass_linear_transform);
NEXT_PASS (pass_graphite_transforms);
NEXT_PASS (pass_iv_canon);
NEXT_PASS (pass_if_conversion);
NEXT_PASS (pass_vectorize);
{
struct opt_pass **p = &pass_vectorize.pass.sub;
NEXT_PASS (pass_lower_vector_ssa);
NEXT_PASS (pass_dce_loop);
}
NEXT_PASS (pass_complete_unroll);
NEXT_PASS (pass_parallelize_loops);
NEXT_PASS (pass_loop_prefetch);
NEXT_PASS (pass_iv_optimize);
NEXT_PASS (pass_tree_loop_done);
}
NEXT_PASS (pass_cse_reciprocals);
NEXT_PASS (pass_convert_to_rsqrt);
NEXT_PASS (pass_reassoc);
NEXT_PASS (pass_vrp);
NEXT_PASS (pass_dominator);
/* The only const/copy propagation opportunities left after
DOM should be due to degenerate PHI nodes. So rather than
run the full propagators, run a specialized pass which
only examines PHIs to discover const/copy propagation
opportunities. */
NEXT_PASS (pass_phi_only_cprop);
NEXT_PASS (pass_cd_dce);
NEXT_PASS (pass_tracer);
/* FIXME: If DCE is not run before checking for uninitialized uses,
we may get false warnings (e.g., testsuite/gcc.dg/uninit-5.c).
However, this also causes us to misdiagnose cases that should be
real warnings (e.g., testsuite/gcc.dg/pr18501.c).
To fix the false positives in uninit-5.c, we would have to
account for the predicates protecting the set and the use of each
variable. Using a representation like Gated Single Assignment
may help. */
NEXT_PASS (pass_late_warn_uninitialized);
NEXT_PASS (pass_dse);
NEXT_PASS (pass_forwprop);
NEXT_PASS (pass_phiopt);
NEXT_PASS (pass_tail_calls);
NEXT_PASS (pass_rename_ssa_copies);
NEXT_PASS (pass_uncprop);
}
NEXT_PASS (pass_del_ssa);
NEXT_PASS (pass_nrv);
NEXT_PASS (pass_mark_used_blocks);
NEXT_PASS (pass_cleanup_cfg_post_optimizing);
NEXT_PASS (pass_warn_function_noreturn);
NEXT_PASS (pass_free_datastructures);
NEXT_PASS (pass_mudflap_2);
NEXT_PASS (pass_free_cfg_annotations);
NEXT_PASS (pass_expand);
NEXT_PASS (pass_rest_of_compilation);
{
struct opt_pass **p = &pass_rest_of_compilation.pass.sub;
NEXT_PASS (pass_init_function);
NEXT_PASS (pass_jump);
NEXT_PASS (pass_rtl_eh);
NEXT_PASS (pass_initial_value_sets);
NEXT_PASS (pass_unshare_all_rtl);
NEXT_PASS (pass_instantiate_virtual_regs);
NEXT_PASS (pass_into_cfg_layout_mode);
NEXT_PASS (pass_jump2);
NEXT_PASS (pass_lower_subreg);
NEXT_PASS (pass_df_initialize_opt);
NEXT_PASS (pass_cse);
NEXT_PASS (pass_rtl_fwprop);
NEXT_PASS (pass_gcse);
NEXT_PASS (pass_rtl_ifcvt);
/* Perform loop optimizations. It might be better to do them a bit
sooner, but we want the profile feedback to work more
efficiently. */
NEXT_PASS (pass_loop2);
{
struct opt_pass **p = &pass_loop2.pass.sub;
NEXT_PASS (pass_rtl_loop_init);
NEXT_PASS (pass_rtl_move_loop_invariants);
NEXT_PASS (pass_rtl_unswitch);
NEXT_PASS (pass_rtl_unroll_and_peel_loops);
NEXT_PASS (pass_rtl_doloop);
NEXT_PASS (pass_rtl_loop_done);
*p = NULL;
}
NEXT_PASS (pass_web);
NEXT_PASS (pass_jump_bypass);
NEXT_PASS (pass_cse2);
NEXT_PASS (pass_rtl_dse1);
NEXT_PASS (pass_rtl_fwprop_addr);
NEXT_PASS (pass_reginfo_init);
NEXT_PASS (pass_inc_dec);
NEXT_PASS (pass_initialize_regs);
NEXT_PASS (pass_outof_cfg_layout_mode);
NEXT_PASS (pass_ud_rtl_dce);
NEXT_PASS (pass_combine);
NEXT_PASS (pass_if_after_combine);
NEXT_PASS (pass_partition_blocks);
NEXT_PASS (pass_regmove);
NEXT_PASS (pass_split_all_insns);
NEXT_PASS (pass_lower_subreg2);
NEXT_PASS (pass_df_initialize_no_opt);
NEXT_PASS (pass_stack_ptr_mod);
NEXT_PASS (pass_mode_switching);
NEXT_PASS (pass_see);
NEXT_PASS (pass_match_asm_constraints);
NEXT_PASS (pass_sms);
NEXT_PASS (pass_sched);
NEXT_PASS (pass_subregs_of_mode_init);
NEXT_PASS (pass_ira);
NEXT_PASS (pass_subregs_of_mode_finish);
NEXT_PASS (pass_postreload);
{
struct opt_pass **p = &pass_postreload.pass.sub;
NEXT_PASS (pass_postreload_cse);
NEXT_PASS (pass_gcse2);
NEXT_PASS (pass_split_after_reload);
NEXT_PASS (pass_branch_target_load_optimize1);
NEXT_PASS (pass_thread_prologue_and_epilogue);
NEXT_PASS (pass_rtl_dse2);
NEXT_PASS (pass_rtl_seqabstr);
NEXT_PASS (pass_stack_adjustments);
NEXT_PASS (pass_peephole2);
NEXT_PASS (pass_if_after_reload);
NEXT_PASS (pass_regrename);
NEXT_PASS (pass_cprop_hardreg);
NEXT_PASS (pass_fast_rtl_dce);
NEXT_PASS (pass_reorder_blocks);
NEXT_PASS (pass_branch_target_load_optimize2);
NEXT_PASS (pass_leaf_regs);
NEXT_PASS (pass_split_before_sched2);
NEXT_PASS (pass_sched2);
NEXT_PASS (pass_stack_regs);
{
struct opt_pass **p = &pass_stack_regs.pass.sub;
NEXT_PASS (pass_split_before_regstack);
NEXT_PASS (pass_stack_regs_run);
}
NEXT_PASS (pass_compute_alignments);
NEXT_PASS (pass_duplicate_computed_gotos);
NEXT_PASS (pass_variable_tracking);
NEXT_PASS (pass_free_cfg);
NEXT_PASS (pass_machine_reorg);
NEXT_PASS (pass_cleanup_barriers);
NEXT_PASS (pass_delay_slots);
NEXT_PASS (pass_split_for_shorten_branches);
NEXT_PASS (pass_convert_to_eh_region_ranges);
NEXT_PASS (pass_shorten_branches);
NEXT_PASS (pass_set_nothrow_function_flags);
NEXT_PASS (pass_final);
}
NEXT_PASS (pass_df_finish);
}
NEXT_PASS (pass_clean_state);
*p = NULL;
RTL
(insn 27 26 0 quicksort/quicksort_cbc.cbc:29 (parallel [
(set (reg/f:SI 7 sp)
(plus:SI (reg/f:SI 7 sp)
(const_int -1024 [0xfffffc00])))
(clobber (reg:CC 17 flags))
]) -1 (nil))
RTLからアセンブラに変換する処理
(define_insn "cmpdi_ccno_1_rex64"
[(set (reg FLAGS_REG)
(compare (match_operand:DI 0 "nonimmediate_operand" "r,?mr")
(match_operand:DI 1 "const0_operand" "")))]
"TARGET_64BIT && ix86_match_ccmode (insn, CCNOmode)"
"@
test{q}\t%0, %0
cmp{q}\t{%1, %0|%0, %1}"
[(set_attr "type" "test,icmp")
(set_attr "length_immediate" "0,1")
(set_attr "mode" "DI")])
(define_insn "*cmpdi_minus_1_rex64"
[(set (reg FLAGS_REG)
(compare (minus:DI (match_operand:DI 0 "nonimmediate_operand" "rm,r")
(match_operand:DI 1 "x86_64_general_operand" "re,mr"))
(const_int 0)))]
"TARGET_64BIT && ix86_match_ccmode (insn, CCGOCmode)"
"cmp{q}\t{%1, %0|%0, %1}"
[(set_attr "type" "icmp")
(set_attr "mode" "DI")])
取り組み
軽量継続を実装するには?
末尾呼出をGCCに強制させる必要がある
末尾呼出ってなに?
末尾呼出ってなに?
軽量継続ではこの末尾呼出(TCE)を強制する!
末尾呼出による軽量継続の実装
goto cs(20, 30);cs(20, 30); return;ある条件で末尾呼出が行われなくなる
末尾呼出による軽量継続の実装
goto cs(20, 30);cs(20, 30); return;ある条件で末尾呼出が行われなくなる
引数順序の問題の解決
code somesegment(int a, int b, int c) {
/∗ do something ∗/
goto nextsegment(b, c, a);
}
(a,b,c) = (b,c,a)と本質的に同じ。これが並列代入a=b,b=c,c=aではだめ。aの値が失われる全ての引数を一時変数に退避
code somesegment(int a, int b, int c) {
int a1, b1, c1;
/∗ do something ∗/
a1=a; b1=b; c1=c;
goto nextsegment(b1, c1, a1);
}
これで軽量継続が実装された
軽量継続は実装されたが、やはりmicro-cに比べると遅い
fastcallの導入
fastcallの強制
__code current(int a, int b, int c) __attribute__((fastcall));
実際の出力はどうなる?
__code current(int a, int b, int c) {
goto next(10, 20, 30);
}
実際の出力アセンブラ
fastcallにした場合
current:
subl $12, %esp
movl $30, 16(%esp)
movl $20, %edx
movl $10, %ecx
addl $12, %esp
jmp next
normalcallの場合
current:
pushl %ebp
movl %esp, %ebp
movl $30, 16(%ebp)
movl $20, 12(%ebp)
movl $10, 8(%ebp)
leave
jmp next
CbCGCCとmicro-cで性能の比較
実行環境
速度測定結果(単位:秒)
| 新CbCGCC | 旧CbCGCC | |||
|---|---|---|---|---|
| 最適化無し | 最適化有り | 最適化無し | 最適化有り | |
| x86/OS X | 5.907 | 2.434 | 4.668 | 3.048 |
| x86/Linux | 5.715 | 2.401 | 4.525 | 2.851 |
評価
速度測定結果(単位:秒)
| 最適化なしのGCC | 最適化付きのGCC | micro-c | |
| x86/OS X | 5.901 | 2.434 | 2.857 |
| x86/Linux | 5.732 | 2.401 | 2.254 |
| ppc/OS X | 14.875 | 2.146 | 4.811 |
| ppc/Linux | 19.793 | 3.955 | 6.454 |
| ppc/PS3 | 39.176 | 5.874 | 11.121 |
結果(micro-cとの比較)
結果(micro-cとの比較)
この違いはどこから?
ファイルサイズの比較
結果
| CbCGCC 速度最適化 |
CbCGCC サイズ最適化 |
micro-c | |
|---|---|---|---|
| x86/OS X | 9176 | 9176 | 9172 |
| x86/Linux | 5752 | 5752 | 5796 |
| ppc/OS X | 8576 | 8576 | 12664 |
| ppc/Linux | 10068 | 10068 | 9876 |
| ppc/PS3 | 6960 | 6728 | 8636 |
結果考察
なぜそれが必要か
環境付き継続の導入
typedef code (*NEXT)(int);
int main(int argc, char **argv) {
int i,a;
i = atoi(argv[1]);
a = factor(i);
printf("%d! = %d\n", a);
}
int factor(int x) {
NEXT ret = __return;
goto factor0(1, x, ret);
}
code
factor0(int prod,int x,NEXT next) {
if (x >= 1) {
goto factor0(prod*x, x-1, next);
} else {
goto (*next)(prod);
}
}
環境付き継続の使用例
__retunrで表される特殊なコードセグメント__returnに継続すると、元の関数の環境にリターンどのように実装する?
内部関数が使いやすい
具体的には
__returnが参照された場合にGCCが自動で内部関数を定義するint factor(int x) {
int retval;
code __return(int val) {
retval = val;
goto label;
}
if (0) {
label:
return retval;
}
NEXT ret = __return;
goto factor0(1, x, ret);
} この取り組みにより
GCCのアップデートリリースは早い
このリリースに追従して差分をアップデートしたい

二つのリポジトリ管理
アップデート手順
これまでのアップデートは
新しい管理方法により
本研究での取り組み
本研究での成果
CbC言語の今後
ありがとうございました
本当に最適化で余分なコードが消えるのか?
_test:
stwu r1,-64(r1)
mr r30,r1
stw r3,88(r30)
stw r4,92(r30)
stw r5,96(r30)
lwz r0,92(r30)
stw r0,32(r30)
lwz r0,96(r30)
addic r0,r0,1
stw r0,28(r30)
lwz r0,88(r30)
stw r0,24(r30)
lwz r3,32(r30)
lwz r4,28(r30)
lwz r5,24(r30)
addi r1,r30,64
lwz r30,-8(r1)
lwz r31,-4(r1)
b L_next$stub
_test:
mr r0,r3
mr r3,r4
mr r4,r5
mr r5,r0
b L_next$stub
CbCとCの比較に関して