概要
非破壊的木構造データベースJungleに分散実装を行い掲示板システムに特化したデーターベースを作成し、その評価を行った。
分散データベースCassandraより2倍以上速く、分散環境下においては10倍以上速くなる結果も確認された。
研究の背景と目的
ウェブサービスにとってデータベースは必須であり、ウェブサービスの規模に比例してデータベースへの負荷も高まる。
データベースの処理能力の高さはそのままウェブサービスの質に繋がるため、データベースのスケーラビリティの確保は重要である。
スケーラビリティ確保の方法としてデータ分散があるが、分散する方法により性能も変わってくる。
ウェブサービスのなかでも、コンテンツマネジメントシステムに合ったスケーラビリティの確保ができるデータベースの開発を行う。
ウェブサービスにおけるデータベースの重要性
ウェブサービスへの負荷が高まることは、データベースへの負荷が高まることでもある。
データベースの性能が低ければ負荷に耐え切れずサービスはダウンする
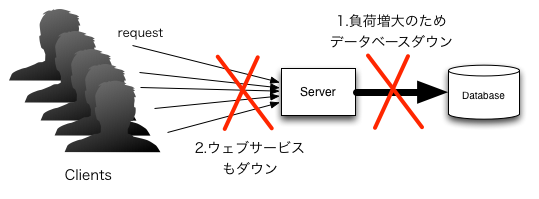
そのため、データベースにはスケーラビリティが必要
スケーラビリティとは
システムが負荷の増大に対して柔軟に拡張して対応できる性質
主に次の2つの方法によりシステムはスケールされる
- スケールアップ:
高価な単一マシンによる性能アップ
- スケールアウト:
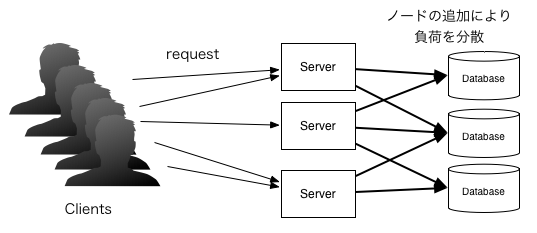
汎用的なマシンを複数台用意することで性能アップ
分散システムにおいてはスケールアウトによりスケーラビリティを高める
データベースのスケーラビリティ
データベースのスケーラビリティを考えるとき、どういう用途で使用するかを考えるのが重要。
例えば、掲示板システムにおいては、書き込みと読み込みが速いことが求められる。
ウェブサービスにおいても、どのようなサービスを行うかによってスケーラビリティの確保の仕方も変わってくる。
本研究で開発しているデータベースはコンテンツマネジメントシステム(CMS)を対象としている。
コンテンツマネジメントシステム(CMS)
Webコンテンツを構成するテキストや画像などのデジタルコンテンツを管理し配信するシステム。
例:ブログツール、Wiki
分散コンテンツマネジメントシステムに求められること。
Webコンテンツを分散して管理
スケールアウトするシステム
データ全体の整合性に遅延がある、結果整合性でもよい。書き込みや読み込みを優先としたデータベースが必要。
そこで、非破壊的木構造データベースJungleの開発が行われた。
非破壊的木構造データベースJungle
JungleはスケーラビリティのあるCMSの設計を目指して当研究室で開発されているデータベース。
データを木構造で、さらに非破壊で保持する。
非破壊的木構造
非破壊的木構造は一度作成したデータは変更しない
新しい木構造を作成することでデータの編集を行う
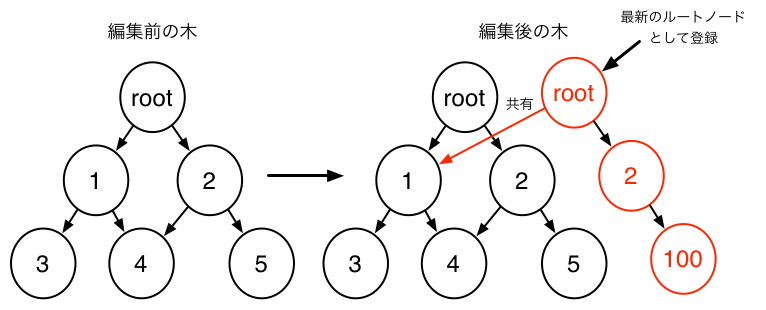
非破壊的木構造の利点
非破壊的木構造は通常の木構造である破壊的木構造に比べ、以下のような利点を持つ
- 一度作成したデータは変更されない
- データが変更されないため自由にコピーを作ることができる(いつでも読み込みが可能)
- ロックがすくない。ロックが必要なのは最新のルートノードを登録するときだけ
ロックが少なく、いつでもコピーが可能なことから、非破壊的木構造はスケーラブルなシステムに有用となる
Jungleの分散設計
ここまでJungleに実装されている非破壊的木構造の利点について述べた。
次に、Jungleにおける分散設計について述べる。
データ分散を行うにあたり、まず考えることはトポロジーの形成と他のノードからデータの伝搬の仕方である。
Jungleはこの問題に対し、ツリートポロジーを形成し、データ編集の際に発生するオペレーションを他のノードに流すことで解決する。
Jungleトポロジーの形成
Jungleのトポロジー形成には当研究室で開発している並列分散フレームワークAliceを使用する。
Aliceは以下の機能が提供されている
- 複数のノードによる分散トポロジーの設定
- トポロジー上でのデータアクセス機構
JungleにAliceを組み込み、Jungleのノード同士でトポロジーを形成する。
Aliceの機能である他ノードへのデータアクセス機構を使用してデータ分散を行う。
分散設計: データ編集オペレーション
Aliceにより、ネットワークトポロジーの作成と他サーバが持つデータアクセス機構を実装できた。
次はどのデータを取得することでデータの分散を行うか考えなければならない。
Jungleにはデータ編集に使われるオペレーションがある。
データ編集に使われるオペレーションをそのまま他サーバノードへ流すことでデータの分散が行える。
オペレーションには次の4つがある
- addNewChild:子ノードの追加を行う
- deleteChildAt:指定したノードの削除を行う
- putAttribute:子ノードにattributeに追加を行う
- deleteAttribute:子ノードのattributeを削除する
データ編集オペレーション
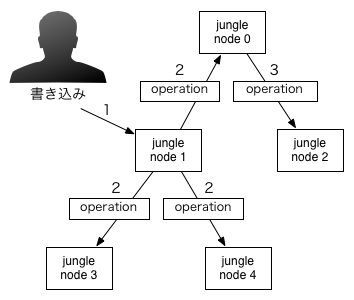
子ノードを追加し、その子ノードにattributeを追加する場合次のノードオペレーションが実行される。
- [APPEND_CHILD:<-1>:pos:0]
- [PUT_ATTRIBUTE:<-1,0>:key:mes,value:hello]
このノードオペレーションの実行結果を図に示す。

トポロジー上でノードオペレーションを渡すことで同じ編集を行いデータの分散を行う。
Jungle分散実装
以上の設計を元にJungleに分散実装を行った。
以下の図はJungleにおけるデータ分散の様子を表している。
Aliceでトポロジーを形成後は、データ編集に使われたオペレーションを他サーバノードに送られる。
オペレーションを受信したノードはデータ編集を行う。他にサーバが繋がっている場合はそちらにもオペレーションを送る。
Jungle分散実装
これまでの実装でJungleのデータが分散が行われるようになった。
しかしもう1つ問題がある。複数のノードから書き込まれるデータの整合性を取る方法が必要である。
JungleではこれをMergeを使うことで自動的に解決する。
Mergeとは2つ以上の変更の結果を受けて1つの変更に変えることである。
今回は、性能比較に用いる掲示板システムにMergeの実装を行った。
掲示板システムにおけるMergeを説明する。
掲示板システムにおけるMerge
2つの状態をもつ掲示板の書き込みができる。この2つの書き込みから新しい書き込みを作る。

掲示板はcommutativeなため、いつ書き込んでも良い。よってMergeが自動的に行える。
分散データベースJungleの評価
分散データベースとしてJungleの性能を評価する。
分散Key-ValueデーターべースCassandraと比較を行う。
比較方法は、Jungle, Cassandra をそれぞれバックエンドとした簡易掲示板を作成する。
掲示板に対してHTTP Requestで並列に読み込みと書き込みの負荷をかけ計測する。
レスポンスが返る平均時間と標準偏差を求めグラフ化する
実験内容
実験は2つ行う
実験1:サーバを単体で起動し、複数のクライアントからの負荷をかける。
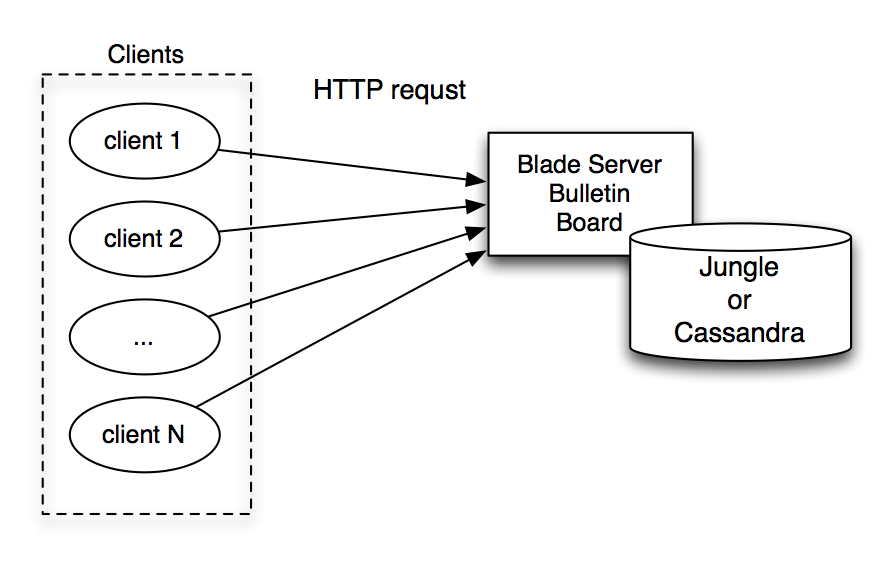
サーバ単体の性能を比較する。
クライアントの増加に対してサーバ1台にかかるリクエストも増加
実験内容
実験2:サーバを単体で起動し、複数のクライアントからの負荷をかける。
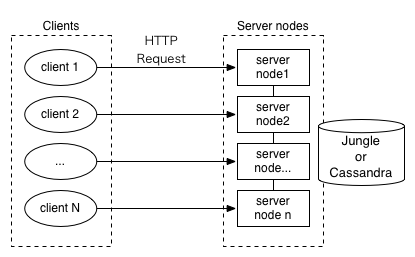
分散環境下における性能を比較する。
クライアントとサーバがともに増加するため、サーバ一台に対するリクエストは変わらず。
サーバが全体で受けるリクエストは増加する。
実験1:単体サーバへの負荷
レスポンス速度(縦軸の数値)が低い程良い
クライアント(横軸の数値)の増加に対してレスポンス速度の増加がゆるやかなものほどよい
単体サーバへの負荷:読み込み負荷
Cassandraに比べJungleが全体的に良い結果を出している。
台数が増える毎にJungleとCassandraの平均時間の差は離れている。
単体サーバへの負荷:書き込み負荷
読み込み同様JungleがCassandraよりもより結果を出している。
読み込み以上にCassandraとの差がついている。
実験1の考察
読み込み、書き込みともにJungleの性能がよく。平均だけみても2倍以上早い部分もある。
特に書き込みに関してはクライアントの数が増えるにつれ差が開いている。
これはJungleが全体的にロックが少ないことが要因としてあげられる。
なぜロックが少ないか
Jungleは非破壊でデータの保持をするため、読み込みは自由に行える。書き込み時には木のコピーをとりルートノードを入れ替える
ときのみロックが発生する。
実験2の考察
こちらもJungleがCassadraより良い結果を示した。実験1よりも差がでている。
Jungleのグラフが横ばいになっていることに注目したい。
Jungleはリクエストに対し手元にあるデータを返す。そのためノードの数が増えてもレスポンスの早さを維持できる。
Cassandraはデータを持っている数台のノードに読み込みに行くという作業が入るためJungleより遅くなってしまう
ただしJungleは全て非同期でデータの伝搬を行うため、データ全体の整合性は落ちる
まとめ
本研究では非破壊的木構造Jungleに分散データベースの実装を行った
非破壊的木構造における利点を述べ、分散実装を行った。
分散実装ではAliceを用いたトポロジー形成により、他ノードへデータ編集のオペレーションを送ることで
実装を行った。
データの整合性に関してはJungle側がMergeにより自動的にMergeを行うことで解決することを述べた。
Mergeアルゴリズムの1つとして掲示板プログラムにおけるMergeについて設計・実装を行った
性能比較の実験のためJungle、Cassandraで利用できる簡易掲示板の作成を行った
実験は単体サーバと分散環境下において行い、どちらともCassandraより平均時間が最低でも2倍以上速いという結果を示すことができた。
分散Key-ValueストアCassandraの特徴
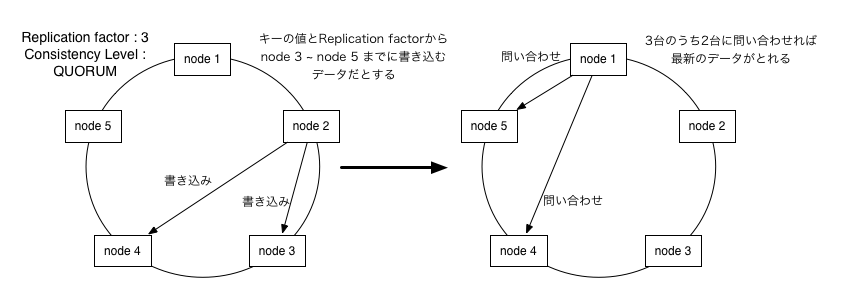
ring型トポロジーを形成。ring上にはHash値があり、書き込むデータのキーのハッシュ値により書き込むノードを決定
1つのデータの複製を最大何とるかというReplication factorの設定がある。
Consistency Levelというデータの読み書きの際に何台のノードから読み書きするかを決定できる
Consistency LevelにはONE,QUORUM,ALLがある。QUORUMはReplication factorの数/2+1 のノードに読み書きする。