関数型言語 Haskell による並列データベースの実装
Daichi TOMA
Feb 4, 2014
Daichi TOMA
Feb 4, 2014
Haskell を用いて並列データベースを実装した。
読み込みに関して 12 コアで実行した場合、10.77 倍 という性能向上率が確認できた。
また、Web 掲示板サービスを開発し、Java より読み込みで 1.87 倍、書き込みで 2.3倍の性能が確認できた。
Web サービスの脆弱性を悪用されると多大な被害がでる
Haskell は型検査でバッファオーバーフローや、クロスサイトスクリプティング、SQL インジェクションを防げる
Haskell を用いてデータベースと Web サービスの開発を行う
Haskellは純粋関数型プログラミング言語
純粋とは、引数が同じならば関数が必ず同じ値を返す
fib :: Int −> Int fib 0 = 0 fib 1 = 1 fib n = fib (n-2) + fib (n-1)
Haskellは、評価の際に型に起因するエラーが起きない
[1,2,3]のリストに文字'a'を追加することはできない
コンパイル時にエラーになる
abc = 'a' : [1,2,3]
-- リスト型の定義 data [] a = [] | a : [a]
Haskell が型を推論してくれる
getChildren node path = elems (children (getNode node path))
*Jungle> :type getChildren getChildren :: Node -> Path -> [Node]
文脈を保ったまま関数を繋いでいくことができる
data Maybe a = Nothing | Just a
instance Monad Maybe where
return x = Just x
Nothing >>= f = Nothing
Just x >>= f = f x
up 4 = Nothing up n = Just (n + 1) down 0 = Nothing down n = Just (n - 1)
return 3 >>= down >>= down >>= up >>= up
return 3 >>= down >>= down >>= up >>= up
updown :: Maybe Int
updown = case down 3 of
Nothing -> Nothing
Just place1 -> case down place1 of
Nothing -> Nothing
Just place2 -> case up place2 of
Nothing -> Nothing
Just place3 -> up place3
現在、CPU はマルチコア化が進んでいる。
マルチコアプロセッサで線形に性能向上をするためには、処理全体で高い並列度を保つ必要性(アムダール則)
並列度が 80 % の場合、どんなにコア数を増やしても性能向上は5倍まで
データベースを線形に性能向上させたければ、各コアからデータに同時にアクセスできるようにし並列度を高める
非破壊的木構造という手法を使う
元となる木構造を書き換えずに編集できる
既にあるデータを変更しないので、データの競合状態が発生しない。並列に読み書きできる
どの木構造が最新なのかを表す情報
状態を持つのはここだけで、並列度を高めるにはここの設計が重要

できるだけルートノードに触る範囲を狭くする
ルートノードが必要ない時はさわらない
ルートノードを更新する関数と、編集する関数を綺麗に切り分ける
ソフトウェア・トランザクショナル・メモリ (STM) を使う
STM は、排他制御を行わずに共有データを扱える
STM は、他のスレッドによる変更を考慮せずに共有データを変更する
変更をトランザクションとしてコミットする時に以下のことがひとつだけ起こる
Jungle は、非破壊的木構造を扱う並列データベース
-- Jungle のデータ型 data Jungle = Jungle (TVar (Map String Tree)) -- Tree のデータ型 data Tree = Tree (TVar Node) String -- Node のデータ型 data Node = Node (Map Int Node) (Map String ByteString)
TVarがついてるのはSTMを使ってる変数
Map は連想配列
Jungle は Tree と String の連想配列を持っている(状態変数)
Tree は、ルートノードの情報と、木の名前(ルートノードの情報は状態変数)
Node は、子と子の場所の連想配列と、キーと値の連想配列を持ってる。

createJungle :: IO Jungle createTree :: Jungle -> String -> IO () getRootNode :: Jungle -> String -> IO Node updateRootNode :: Jungle -> String -> Node -> IO () updateRootNodeWith :: (Node -> Node) -> Jungle -> String -> IO ()
すべて IO が返ってくる 後回しで性能計測からまとめる
Jungle がマルチコアプロセッサで性能が出るのか、実用的なWebサービスが提供できるのか確認する
性能の計測に用いるサーバの仕様
ハイパースレッディングで24コアまで使える
| 名前 | 概要 |
|---|---|
| CPU | Intel(R) Xeon(R) CPU X5650@2.67GHz * 2 |
| コア数 | 12 |
| メインメモリ | 126 GB |
| OS | Fedora 14 |
木構造の読み込みにかかる時間を計測する
12 スレッドで実行時に 10.77 倍の性能向上
ハイパースレッディングは遅くなったりと安定しない
| CPU数 | 実行時間 |
|---|---|
| 1 | 59.77 s |
| 2 | 33.36 s |
| 4 | 15.63 s |
| 8 | 8.10 s |
| 12 | 5.55 s |
| 16 | 5.65 s |
| 20 | 5.23 s |
| 24 | 5.77 s |
12 スレッドまでの性能向上率

木構造の書き込みにかかる時間を計測する
2 スレッドで 1.55 倍の性能向上
12 スレッドで実行時に 3.86 倍の性能向上
ハイパースレッディングは12スレッド以降遅くなっている
| CPU数 | 実行時間 |
|---|---|
| 1 | 52.68 s |
| 2 | 33.92 s |
| 4 | 20.11 s |
| 8 | 15.31 s |
| 12 | 13.62 s |
| 16 | 14.92 s |
| 20 | 18.62 s |
| 24 | 16.63 s |
12 スレッドまでの性能向上率
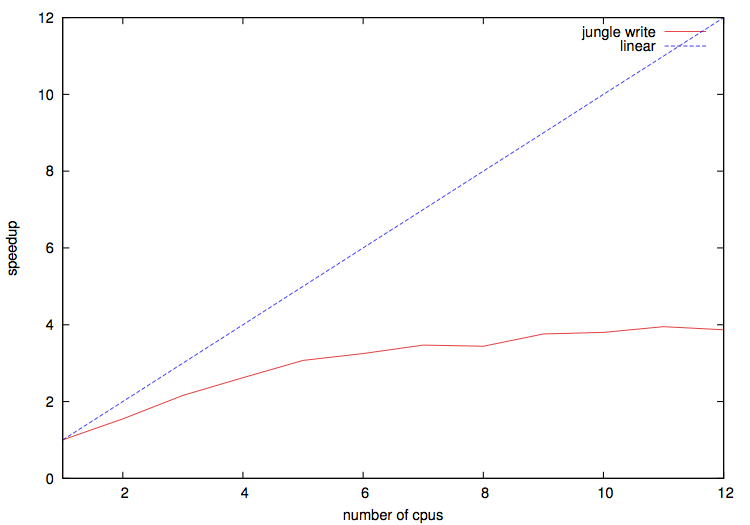
読み込みと比べて書き込みの性能向上率が低い
木を登録する際、他のスレッドから登録があった場合、ソフトウェア・トランザクショナル・メモリが処理をやり直すため遅いと考えられる。
書き込みより読み込みが多用されるシステムに向いている。
Haskell の HTTP サーバ Warp と組み合わせて Web掲示板サービスを開発する。
weighttpを用いて掲示板に読み込みと書き込みで負荷をかける。リクエストの総数は100万
Warp は、ハイパースレッディングで明らかに遅くなるので、12コアまでの計測とする。
読み込み
12 スレッド時に 2.14 倍
性能向上率が低い
| CPU数 | 実行時間 |
|---|---|
| 1 | 60.72 s |
| 2 | 37.74 s |
| 4 | 28.97 s |
| 8 | 27.73 s |
| 12 | 28.33 s |
書き込み
12 スレッド時に 1.65 倍
読み込みよりさらに悪い
| CPU数 | 実行時間 |
|---|---|
| 1 | 54.16 s |
| 2 | 36.71 s |
| 4 | 31.74 s |
| 8 | 31.58 s |
| 12 | 32.68 s |
Warp がボトルネックとなってしまっている。 Warp は現状あまり並列化効果がでていない。
アクセスした際に、"hello, world" という文字列を返すだけのプログラムを作成し計測する。
Jungle を組み込んだ時と比較して、読み込みの場合はほとんど差がない。
| CPU数 | 実行時間 |
|---|---|
| 1 | 49.28 s |
| 2 | 35.45 s |
| 4 | 25.70 s |
| 8 | 27.90 s |
| 12 | 29.23 s |
| 測定 | Haskell | Java |
|---|---|---|
| 読み込み | 28.33 s | 53.13 s |
| 書き込み | 32.68 s | 76.4 s |
読み込みで 1.87 倍、書き込みで 2.3 倍の性能差が出ている
書き込みが読み込みより性能差が出ている理由として遅延評価が考えられる。 Haskell では書き込みを行う際、完全に評価せず途中式を積み上げていく。